05 - Resampling Methods
Libraries
Conceptual
1
1. Using basic statistical properties of the variance, as well as single-variable calculus, derive (5.6). In other words, prove that \(\alpha\) given by (5.6) does indeed minimize \(\text{Var}(\alpha X + (1-\alpha)Y)\).
By taking as a reference the Propagation section of the Variance Wikipedia post.
\[ \begin{split} \text{Var}(\alpha X + (1-\alpha)Y) & = \alpha^2 \text{Var}(X)+ (1-\alpha)^2 \text{Var}(Y) + 2 \alpha (1-\alpha) \text{Cov}(X,Y) \\ & = \alpha^2 \text{Var}(X)+ (1 - 2 \alpha + \alpha^2) \text{Var}(Y) + (2 \alpha-2\alpha^2) \text{Cov}(X,Y) \\ & = \alpha^2 \text{Var}(X)+ \text{Var}(Y) - 2 \alpha \text{Var}(Y) + \alpha^2 \text{Var}(Y)+ 2 \alpha \text{Cov}(X,Y) - 2\alpha^2 \text{Cov}(X,Y) \\ & = [\text{Var}(X) + \text{Var}(Y) - 2 \text{Cov}(X,Y)] \alpha^2 + 2[ \text{Cov}(X,Y) - \text{Var}(Y)] \alpha + \text{Var}(Y) \end{split} \]
Once we have the function, we can derivative using the derivative of power and solve the equation.
\[ \begin{split} 2[\text{Var}(X) + \text{Var}(Y) - 2 \text{Cov}(X,Y)] \alpha + 2[ \text{Cov}(X,Y) - \text{Var}(Y)] & = 0 \\ 2[\text{Var}(X) + \text{Var}(Y) - 2 \text{Cov}(X,Y)] \alpha & = 2[\text{Var}(Y) - \text{Cov}(X,Y)] \\ \alpha = \frac{\text{Var}(Y) - \text{Cov}(X,Y)}{\text{Var}(X) + \text{Var}(Y) - 2 \text{Cov}(X,Y)} \end{split} \]
2
2. We will now derive the probability that a given observation is part of a bootstrap sample. Suppose that we obtain a bootstrap sample from a set of n observations.
A
(A) What is the probability that the first bootstrap observation is not the jth observation from the original sample? Justify your answer.
The probability of an observation to be in any position of the bootstrap sample is \(1/n\) and the opposite \(1 - 1/n\).
B
(B) What is the probability that the second bootstrap observation is not the jth observation from the original sample?
The probability it’s the same (\(1 - 1/n\)) as we are sampling with replacement.
C
(C) Argue that the probability that the jth observation is not in the bootstrap sample is \((1 - 1/n)^n\).
As the probability of the jth observation for avoiding each position in bootstrap sample is \(1 - 1/n\) to get the probability in that situation we should use \((1 - 1/n)^n\) as the probabilities are independent.
D
(D) When \(n = 5\), what is the probability that the jth observation is in the bootstrap sample?
As \((1 - 1/5)^5\) represent the probability that an observation won’t appear.
\[ 1 - (1 - 1/5)^5 = 0.6723 \]
E
(E) When \(n = 100\), what is the probability that the jth observation is in the bootstrap sample?
\[ 1 - (1 - 1/100)^{100} = 0.6340 \]
F
(F) When \(n = 10,000\), what is the probability that the jth observation is in the bootstrap sample?
\[ 1 - (1 - 1/10000)^{10000} = 0.6321 \]
G
(G) Create a plot that displays, for each integer value of n from \(1\) to \(100,000\), the probability that the jth observation is in the bootstrap sample. Comment on what you observe.
ggplot(data.frame(x = 1:1e4))+
geom_function(aes(x), fun = \(x) 1 - (1 - 1/x)^x,
color = "blue", linewidth = 0.8)+
geom_hline(yintercept = 1 - 1/exp(1), linetype = 2,
color = as.character(round(1 - 1/exp(1), 4)))+
expand_limits(y = 0)+
labs(x = "Number of observations",
y = "Probability",
title = "Probability an observation is in the bootstrap sample")+
scale_y_continuous(labels = percent_format(accuracy = 1),
breaks = breaks_width(0.1))+
scale_x_continuous(labels = comma_format(accuracy = 1))+
theme_light()+
theme(panel.grid.minor = element_blank(),
panel.grid.major.x = element_blank(),
plot.title = element_text(hjust = 0.5, face = "bold"))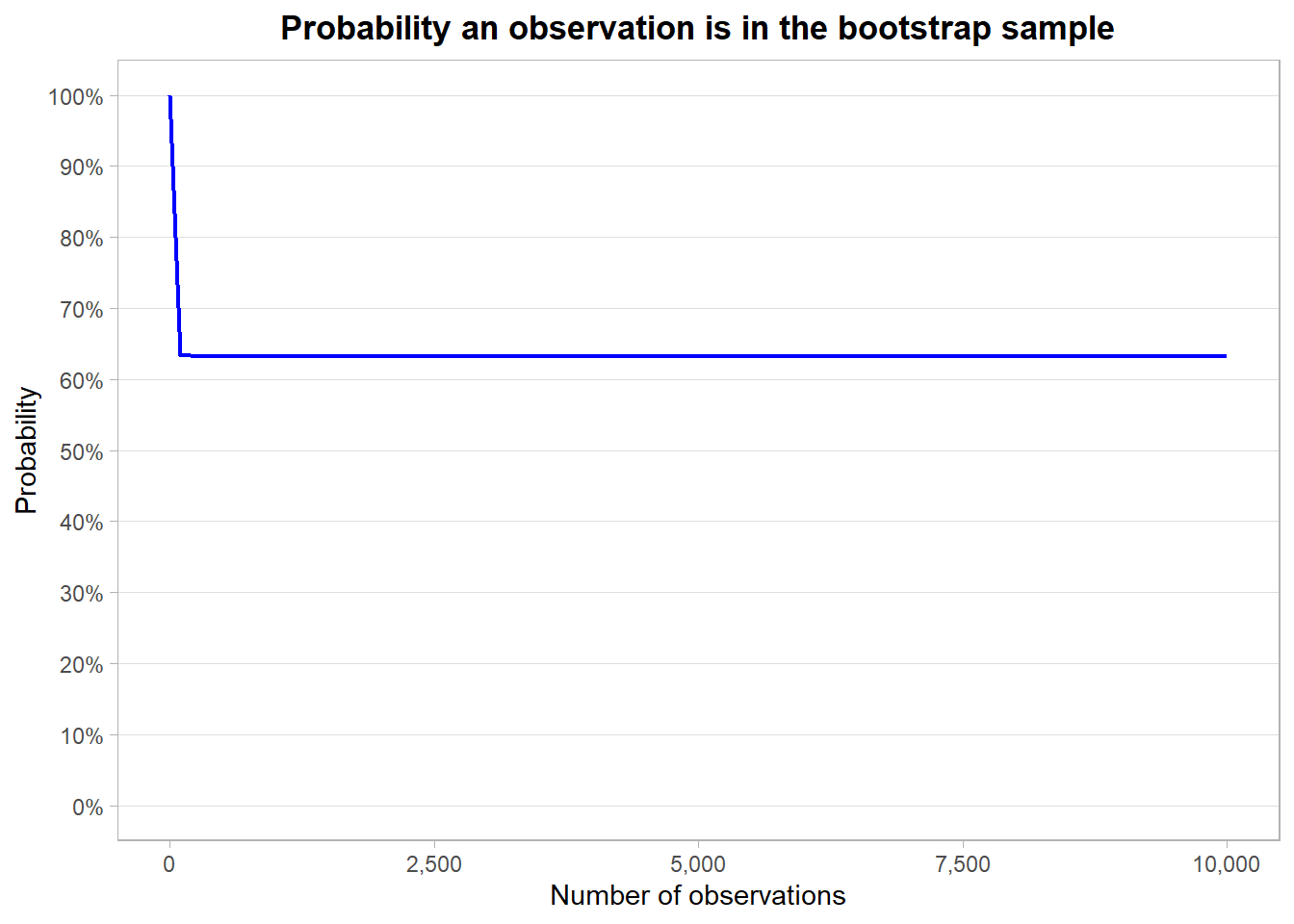
H
(H) We will now investigate numerically the probability that a bootstrap sample of size \(n = 100\) contains the jth observation. Here \(j = 4\). We repeatedly create bootstrap samples, and each time we record whether or not the fourth observation is contained in the bootstrap sample.
set.seed(2018)
vapply(1:1e4,
FUN = \(x) 4L %in% sample.int(100L, 100L, replace = TRUE),
FUN.VALUE = TRUE) |>
mean()[1] 0.6329As we can see the probability es really close to \(0.6340\).
3
3. We now review k-fold cross-validation.
A
(A) Explain how k-fold cross-validation is implemented.
It involves randomly dividing the set of observations into k groups, or folds, of approximately equal size. The first fold is treated as a validation set, and the method is fit on the remaining \(k - 1\) folds.
B
(B) What are the advantages and disadvantages of k-fold cross validation relative to the validation set approach and the LOOCV?
| Main Characteristics | Validation Set Approach | LOOCV |
|---|---|---|
| Accuracy in estimating the testing error | Lower | Lower |
| Time efficiency | Higher | Lower |
| Proportion of data used to train the models (bias mitigation) | Lower | Higher |
| Estimation variance | - | Higher |
4
4. Suppose that we use some statistical learning method to make a prediction for the response Y for a particular value of the predictor X. Carefully describe how we might estimate the standard deviation of our prediction.
I would use to bootstrap method to re-sample the original data set many times, fit a statistical learning method on each re-sample, predict the value based on the predictors we want to study and calculate the standard deviation of the response, which is a good approximation of the standard error as we can on page 210.
Applied
5
5. In Chapter 4, we used logistic regression to predict the probability of default using income and balance on the Default data set. We will now estimate the test error of this logistic regression model using the validation set approach. Do not forget to set a random seed before beginning your analysis.
DefaultFormulaToFit <- as.formula("default ~ balance + income")A
(A) Fit a logistic regression model that uses income and balance to predict default.
DefaultFittedModel <-
logistic_reg() |>
fit(DefaultFormulaToFit, data = ISLR::Default)
DefaultFittedModelparsnip model object
Call: stats::glm(formula = default ~ balance + income, family = stats::binomial,
data = data)
Coefficients:
(Intercept) balance income
-1.154e+01 5.647e-03 2.081e-05
Degrees of Freedom: 9999 Total (i.e. Null); 9997 Residual
Null Deviance: 2921
Residual Deviance: 1579 AIC: 1585B
(B) Using the validation set approach, estimate the test error of this model. In order to do this, you must perform the following steps:
- Split the sample set into a training set and a validation set.
<Training/Testing/Total>
<5000/5000/10000>- Fit a multiple logistic regression model using only the training observations.
DefaultTrainingModel <-
logistic_reg() |>
fit(DefaultFormulaToFit, data = training(DefaultSplit))
DefaultTrainingModelparsnip model object
Call: stats::glm(formula = default ~ balance + income, family = stats::binomial,
data = data)
Coefficients:
(Intercept) balance income
-1.153e+01 5.598e-03 2.384e-05
Degrees of Freedom: 4999 Total (i.e. Null); 4997 Residual
Null Deviance: 1484
Residual Deviance: 813.8 AIC: 819.8- Obtain a prediction of default status for each individual in the validation set by computing the posterior probability of default for that individual, and classifying the individual to the
defaultcategory if the posterior probability is greater than 0.5.
DefaultTestPredictions <-
augment(DefaultTrainingModel, new_data = testing(DefaultSplit))
DefaultTestPredictions# A tibble: 5,000 × 7
.pred_class .pred_No .pred_Yes default student balance income
<fct> <dbl> <dbl> <fct> <fct> <dbl> <dbl>
1 No 1.00 0.000446 No No 529. 35704.
2 No 0.998 0.00202 No Yes 920. 7492.
3 No 0.999 0.00138 No Yes 809. 17600.
4 No 1.00 0.0000198 No No 0 29275.
5 No 1.00 0.0000728 No No 237. 28252.
6 No 0.999 0.000859 No No 607. 44995.
7 No 1.00 0.0000326 No No 0 50265.
8 No 0.999 0.000649 No No 486. 61566.
9 No 0.992 0.00844 No No 1095. 26465.
10 No 0.996 0.00444 No No 954. 32458.
# ℹ 4,990 more rows- Compute the validation set error, which is the fraction of the observations in the validation set that are misclassified.
DefaultTestPredictions |>
summarize(`Test error rate` = mean(default != .pred_class))# A tibble: 1 × 1
`Test error rate`
<dbl>
1 0.0242C
(C) Repeat the process in (b) three times, using three different splits of the observations into a training set and a validation set. Comment on the results obtained.
DefaultBasedResults <-
lapply(8:10,
model_recipe = recipe(DefaultFormulaToFit, data = ISLR::Default),
FUN = \(seed, model_recipe){
set.seed(seed)
split <- initial_split(ISLR::Default, prop = 0.5, strata = default)
workflow() |>
add_model(logistic_reg()) |>
add_recipe(model_recipe) |>
last_fit(split = split) |>
collect_predictions() |>
summarize(seed_used = seed,
`test_error_rate` = mean(.pred_class != default)) }) |>
rbindlist()
DefaultBasedResults seed_used test_error_rate
1: 8 0.0262
2: 9 0.0240
3: 10 0.0282D
(D) Now consider a logistic regression model that predicts the probability of default using income, balance, and a dummy variable for student. Estimate the test error for this model using the validation set approach. Comment on whether or not including a dummy variable for student leads to a reduction in the test error rate.
Adding the student variable as a dummy one doesn’t make a big impact on the prediction accurency.
DefaultDummyRecipe <-
recipe(default ~ ., data = ISLR::Default) |>
step_dummy(student)
DefaultDummyResults <-
lapply(8:10,
model_recipe = DefaultDummyRecipe,
FUN = \(seed, model_recipe){
set.seed(seed)
split <- initial_split(ISLR::Default, prop = 0.5, strata = default)
workflow() |>
add_model(logistic_reg()) |>
add_recipe(model_recipe) |>
last_fit(split = split) |>
collect_predictions() |>
summarize(seed_used = seed,
`test_error_rate_dummy` = mean(.pred_class != default)) }) |>
rbindlist()
DefaultBasedResults[DefaultDummyResults, on = "seed_used"
][, diff := comma(test_error_rate_dummy - test_error_rate, accuracy = 0.0001)][] seed_used test_error_rate test_error_rate_dummy diff
1: 8 0.0262 0.0260 -0.0002
2: 9 0.0240 0.0248 0.0008
3: 10 0.0282 0.0278 -0.00046
6. We continue to consider the use of a logistic regression model to predict the probability of default using income and balance on the Default data set. In particular, we will now compute estimates for the standard errors of the income and balance logistic regression coefficients in two different ways: (1) using the bootstrap, and (2) using the standard formula for computing the standard errors in the glm() function. Do not forget to set a random seed before beginning your analysis.
A
(A) Using the summary() and glm() functions, determine the estimated standard errors for the coefficients associated with income and balance in a multiple logistic regression model that uses both predictors.
DefaultGlmSummary <- tidy(DefaultFittedModel)
DefaultGlmSummary# A tibble: 3 × 5
term estimate std.error statistic p.value
<chr> <dbl> <dbl> <dbl> <dbl>
1 (Intercept) -11.5 0.435 -26.5 2.96e-155
2 balance 0.00565 0.000227 24.8 3.64e-136
3 income 0.0000208 0.00000499 4.17 2.99e- 5B
(B) Write a function, boot.fn(), that takes as input the Default data set as well as an index of the observations, and that outputs the coefficient estimates for income and balance in the multiple logistic regression model.
To create the function it’s optimal
C
(C) Use the boot() function together with your boot.fn() function to estimate the standard errors of the logistic regression coefficients for income and balance.
set.seed(15)
DefaultBootstrapsSe <-
as.data.table(bootstraps(ISLR::Default, times = 500)
)[, logistic_reg() |>
fit(DefaultFormulaToFit,
data = analysis(splits[[1L]])) |>
tidy(),
by = "id"
][, .(SE = sd(estimate)),
by = "term"]
DefaultBootstrapsSe term SE
1: (Intercept) 4.230130e-01
2: balance 2.203893e-04
3: income 4.895823e-06D
(D) Comment on the estimated standard errors obtained using the glm() function and using your bootstrap function.
As you can see bellow the results are really close to each other.
left_join(DefaultBootstrapsSe,
DefaultGlmSummary[,c("term","std.error")],
by = "term") |>
mutate(diff = SE - std.error) term SE std.error diff
1: (Intercept) 4.230130e-01 4.347564e-01 -1.174338e-02
2: balance 2.203893e-04 2.273731e-04 -6.983879e-06
3: income 4.895823e-06 4.985167e-06 -8.934457e-087
7. In Sections 5.3.2 and 5.3.3, we saw that the cv.glm() function can be used in order to compute the LOOCV test error estimate. Alternatively, one could compute those quantities using just the glm() and predict.glm() functions, and a for loop. You will now take this approach in order to compute the LOOCV error for a simple logistic regression model on the Weekly data set. Recall that in the context of classification problems, the LOOCV error is given in (5.4).
A
(A) Fit a logistic regression model that predicts Direction using Lag1 and Lag2.
WeeklyModel <-
logistic_reg() |>
fit(Direction ~ Lag1 + Lag2, data = ISLR::Weekly)
WeeklyModelparsnip model object
Call: stats::glm(formula = Direction ~ Lag1 + Lag2, family = stats::binomial,
data = data)
Coefficients:
(Intercept) Lag1 Lag2
0.22122 -0.03872 0.06025
Degrees of Freedom: 1088 Total (i.e. Null); 1086 Residual
Null Deviance: 1496
Residual Deviance: 1488 AIC: 1494B
(B) Fit a logistic regression model that predicts Direction using Lag1 and Lag2 using all but the first observation.
WeeklyModelNotFirst <-
logistic_reg() |>
fit(Direction ~ Lag1 + Lag2, data = ISLR::Weekly[-1L,])
WeeklyModelNotFirstparsnip model object
Call: stats::glm(formula = Direction ~ Lag1 + Lag2, family = stats::binomial,
data = data)
Coefficients:
(Intercept) Lag1 Lag2
0.22324 -0.03843 0.06085
Degrees of Freedom: 1087 Total (i.e. Null); 1085 Residual
Null Deviance: 1495
Residual Deviance: 1487 AIC: 1493C
(C) Use the model from (b) to predict the direction of the first observation. You can do this by predicting that the first observation will go up if P(Direction = "Up" | Lag1, Lag2) > 0.5. Was this observation correctly classified?
No, it wasn’t.
WeeklyModelNotFirst |>
augment(new_data = ISLR::Weekly[1L,] )# A tibble: 1 × 12
.pred_class .pred_Down .pred_Up Year Lag1 Lag2 Lag3 Lag4 Lag5 Volume
<fct> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 Up 0.429 0.571 1990 0.816 1.57 -3.94 -0.229 -3.48 0.155
# ℹ 2 more variables: Today <dbl>, Direction <fct>D
(D) Write a for loop from \(i = 1\) to \(i = n\), where n is the number of observations in the data set, that performs each of the following steps:
- Fit a logistic regression model using all but the ith observation to predict
DirectionusingLag1andLag2. - Compute the posterior probability of the market moving up for the ith observation.
- Use the posterior probability for the ith observation in order to predict whether or not the market moves up.
- Determine whether or not an error was made in predicting the direction for the ith observation. If an error was made, then indicate this as a 1, and otherwise indicate it as a 0.
WeeklyLoocv <- loo_cv(ISLR::Weekly)
setDT(WeeklyLoocv)
WeeklyLoocvPredictions <-
WeeklyLoocv[, training(splits[[1L]]), by = "id"
][, .(model = .(logistic_reg() |>
fit(Direction ~ Lag1 + Lag2, data = .SD))),
by = "id"
][WeeklyLoocv[, testing(splits[[1L]]), by = "id"],
on = "id"
][, .pred_class := predict(model[[1L]], new_data = .SD, type = "class"),
by = "id"
][, is_error := Direction != .pred_class]E
(E) Take the average of the n numbers obtained in (4d) in order to obtain the LOOCV estimate for the test error. Comment on the results.
mean(WeeklyLoocvPredictions$is_error)[1] 0.44995418
A
(A) Generate a simulated data set as follows. In this data set, what is n and what is p? Write out the model used to generate the data in equation form.
set.seed(1)
x <- rnorm(100)
y <- x- 2*x^2 + rnorm(100)
SimulatedDt <- data.table(x, y)n: 100 and p: 1.
B
(B) Create a scatterplot of X against Y. Comment on what you find.
The values follows a function of second degree.
ggplot(SimulatedDt, aes(x, y))+
geom_point()+
geom_smooth(se = FALSE)+
theme_light()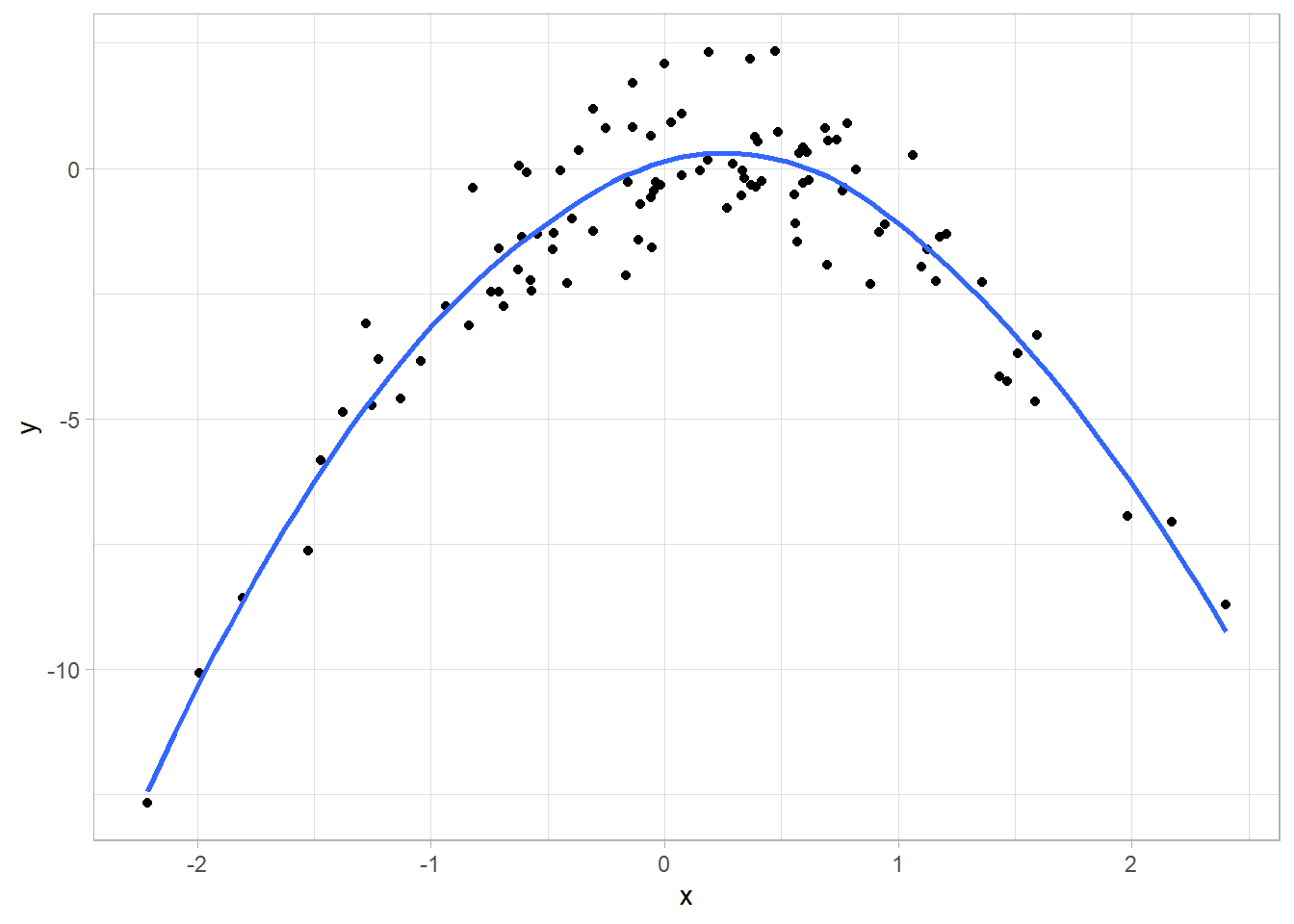
C
(C) Set a random seed, and then compute the LOOCV errors that result from fitting the following four models using least squares. Note you may find it helpful to use the data.frame() function to create a single data set containing both X and Y .
- \(Y = \beta_0 + \beta_1 X + \epsilon\)
- \(Y = \beta_0 + \beta_1 X + \beta_2 X^2 + \epsilon\)
- \(Y = \beta_0 + \beta_1 X + \beta_2 X^2 + \beta_3 X^3 + \epsilon\)
- \(Y = \beta_0 + \beta_1 X + \beta_2 X^2 + \beta_3 X^3 + \beta_4 X^4 + \epsilon\)
we don’t need to set a seed when performing LOOCV, as we don’t do anything at random.
collect_loo_testing_error <- function(formula,
loo_split,
metric_function = rmse,
...){
# Validations
stopifnot("There is no espace between y and ~" = formula %like% "[A-Za-z]+ ")
stopifnot("loo_split must be a data.table object" = is.data.table(loo_split))
predictor <- sub(pattern = " .+", replacement = "", formula)
formula_to_fit <- as.formula(formula)
Results <-
loo_split[, training(splits[[1L]]), by = "id"
][, .(model = .(lm(formula_to_fit, data = .SD))),
by = "id"
][loo_split[, testing(splits[[1L]]), by = "id"],
on = "id"
][, .pred := predict(model[[1L]], newdata = .SD),
by = "id"
][, metric_function(.SD, truth = !!predictor, estimate = .pred, ...) ]
setDT(Results)
if(formula %like% "degree"){
degree <- gsub(pattern = "[ A-Za-z,=\\~()]", replacement = "", formula)
Results <-
Results[,.(degree = degree,
.metric,
.estimator,
.estimate)]
}
return(Results)
}
# Creating the rplit object
SimulatedDtSplit <- loo_cv(SimulatedDt)
# Transforming to data.table
setDT(SimulatedDtSplit)
paste0("y ~ poly(x, degree=", 1:4, ")") |>
lapply(collect_loo_testing_error,
loo_split = SimulatedDtSplit) |>
rbindlist() degree .metric .estimator .estimate
1: 1 rmse standard 2.6996595
2: 2 rmse standard 0.9682064
3: 3 rmse standard 0.9780705
4: 4 rmse standard 0.9766805D
(D) Repeat (c) using another random seed, and report your results. Are your results the same as what you got in (c)? Why?
The results will be the same as LOOCV don’t perform any random process.
E
(E) Which of the models in (c) had the smallest LOOCV error? Is this what you expected? Explain your answer.
The model with the lowest test error is the model using as a base the second grade evacuation. It’s what we were expecting, as we know the true form of the original function it’s a second degree one and adding more flexibility to the model just over-fit it.
F
(F) Comment on the statistical significance of the coefficient estimates that results from fitting each of the models in (c) using least squares. Do these results agree with the conclusions drawn based on the cross-validation results?
For the first model the predictor it’s significant.
Call:
lm(formula = y ~ poly(x, degree = 1), data = SimulatedDt)
Residuals:
Min 1Q Median 3Q Max
-9.5161 -0.6800 0.6812 1.5491 3.8183
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -1.550 0.260 -5.961 3.95e-08 ***
poly(x, degree = 1) 6.189 2.600 2.380 0.0192 *
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 2.6 on 98 degrees of freedom
Multiple R-squared: 0.05465, Adjusted R-squared: 0.045
F-statistic: 5.665 on 1 and 98 DF, p-value: 0.01924For the second model the predictors are very significant.
Call:
lm(formula = y ~ poly(x, degree = 2), data = SimulatedDt)
Residuals:
Min 1Q Median 3Q Max
-1.9650 -0.6254 -0.1288 0.5803 2.2700
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -1.5500 0.0958 -16.18 < 2e-16 ***
poly(x, degree = 2)1 6.1888 0.9580 6.46 4.18e-09 ***
poly(x, degree = 2)2 -23.9483 0.9580 -25.00 < 2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.958 on 97 degrees of freedom
Multiple R-squared: 0.873, Adjusted R-squared: 0.8704
F-statistic: 333.3 on 2 and 97 DF, p-value: < 2.2e-16The additional element of the function is not significant.
Call:
lm(formula = y ~ poly(x, degree = 3), data = SimulatedDt)
Residuals:
Min 1Q Median 3Q Max
-1.9765 -0.6302 -0.1227 0.5545 2.2843
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -1.55002 0.09626 -16.102 < 2e-16 ***
poly(x, degree = 3)1 6.18883 0.96263 6.429 4.97e-09 ***
poly(x, degree = 3)2 -23.94830 0.96263 -24.878 < 2e-16 ***
poly(x, degree = 3)3 0.26411 0.96263 0.274 0.784
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.9626 on 96 degrees of freedom
Multiple R-squared: 0.8731, Adjusted R-squared: 0.8691
F-statistic: 220.1 on 3 and 96 DF, p-value: < 2.2e-16The additional element of the function is not significant.
Call:
lm(formula = y ~ poly(x, degree = 4), data = SimulatedDt)
Residuals:
Min 1Q Median 3Q Max
-2.0550 -0.6212 -0.1567 0.5952 2.2267
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -1.55002 0.09591 -16.162 < 2e-16 ***
poly(x, degree = 4)1 6.18883 0.95905 6.453 4.59e-09 ***
poly(x, degree = 4)2 -23.94830 0.95905 -24.971 < 2e-16 ***
poly(x, degree = 4)3 0.26411 0.95905 0.275 0.784
poly(x, degree = 4)4 1.25710 0.95905 1.311 0.193
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.9591 on 95 degrees of freedom
Multiple R-squared: 0.8753, Adjusted R-squared: 0.8701
F-statistic: 166.7 on 4 and 95 DF, p-value: < 2.2e-169
9. We will now consider the Boston housing data set, from the ISLR2 library.
A
(A) Based on this data set, provide an estimate for the population mean of medv. Call this estimate \(\hat{\mu}\).
B
(B) Provide an estimate of the standard error of \(\hat{\mu}\). Interpret this result. Hint: We can compute the standard error of the sample mean by dividing the sample standard deviation by the square root of the number of observations.
C
(C) Now estimate the standard error of \(\hat{\mu}\). using the bootstrap. How does this compare to your answer from (b)?
Both estimations are really close.
# Using the infer package as just need to estimate
# a single number
set.seed(123)
BostonMedvBootstrap <-
ISLR2::Boston |>
specify(medv ~ NULL) |>
generate(reps = 5000, type = "bootstrap") |>
calculate(stat = "mean")
BostonMedvBootstrap |>
summarize(Se_bootstrap = sd(stat)) |>
mutate(Se_estimation = BostonMedvSeEstimation,
diff = Se_bootstrap - Se_estimation)# A tibble: 1 × 3
Se_bootstrap Se_estimation diff
<dbl> <dbl> <dbl>
1 0.414 0.409 0.00481D
(D) Based on your bootstrap estimate from (c), provide a 95 % confidence interval for the mean of medv. Compare it to the results obtained using t.test(Boston$medv). Hint: You can approximate a 95 % confidence interval using the formula [\(\hat{\mu} - 2\text{SE}(\hat{\mu}), \hat{\mu} + 2\text{SE}(\hat{\mu})\) .
get_ci(BostonMedvBootstrap,
point_estimate = BostonMedvMean,
level = 0.95,
type = "se")# A tibble: 1 × 2
lower_ci upper_ci
<dbl> <dbl>
1 21.7 23.3E
(E) Based on this data set, provide an estimate, \(\hat{\mu}_{med}\), for the median value of medv in the population.
F
(F) We now would like to estimate the standard error of \(\hat{\mu}_{med}\). Unfortunately, there is no simple formula for computing the standard error of the median. Instead, estimate the standard error of the median using the bootstrap. Comment on your findings.
The intervals for the median seams to be a little bit lower than the ones for the average. It seems the distributions of medv is right skewed.
set.seed(77)
ISLR2::Boston |>
specify(medv ~ NULL) |>
generate(reps = 5000, type = "bootstrap") |>
calculate(stat = "median") |>
get_ci(level = 0.95,
type = "percentile")# A tibble: 1 × 2
lower_ci upper_ci
<dbl> <dbl>
1 20.5 21.9Right skewed has been confirmed.
ggplot(ISLR2::Boston, aes(medv))+
geom_histogram(fill = "dodgerblue3",
alpha = 0.9, bins = 15)+
theme_light()+
theme(panel.grid = element_blank())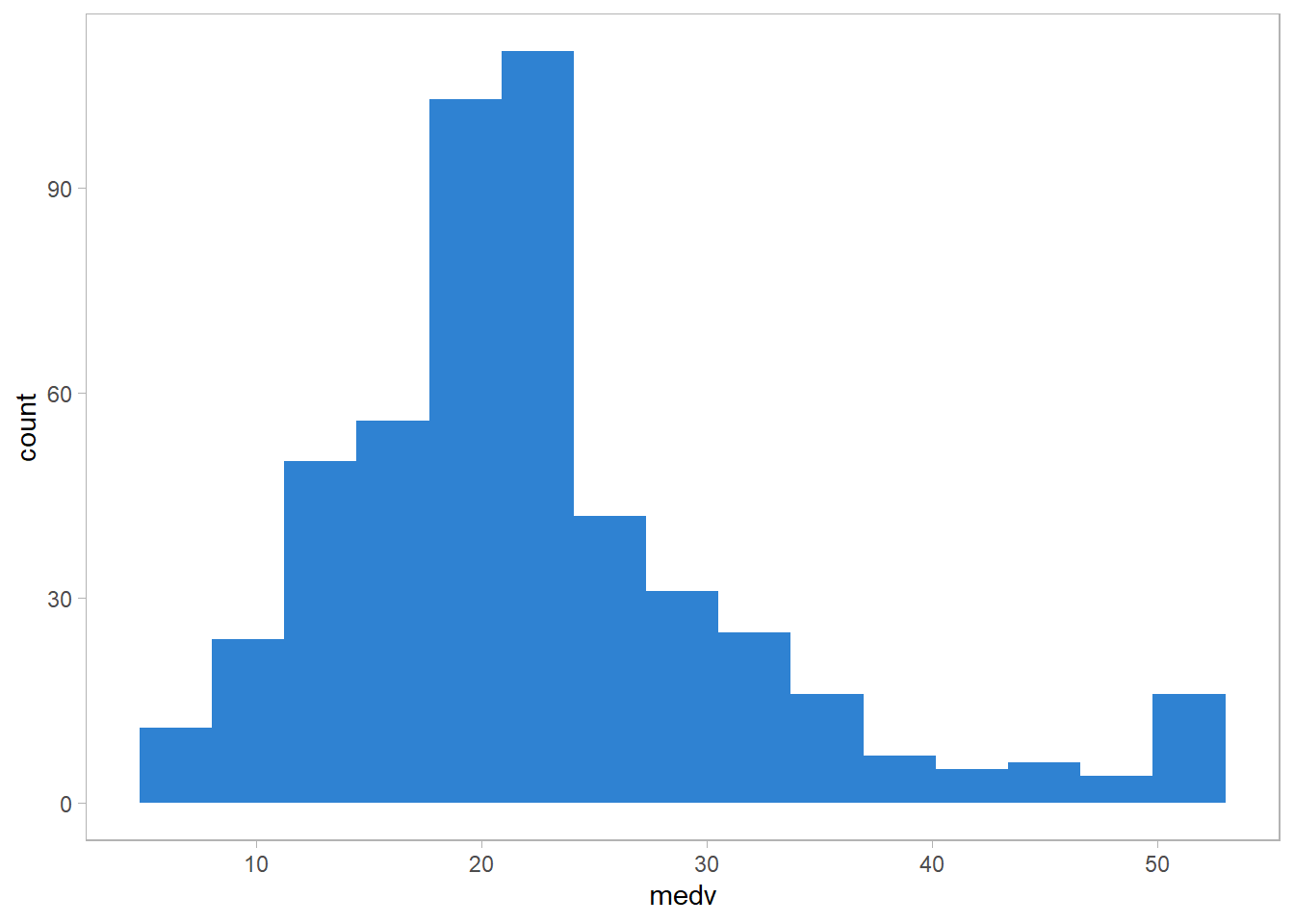
G
(G) Based on this data set, provide an estimate for the tenth percentile of medv in Boston census tracts. Call this quantity \(\hat{\mu}_{0.1}\). (You can use the quantile() function.)
H
(H) Use the bootstrap to estimate the standard error of \(\hat{\mu}_{0.1}\). Comment on your findings.
The standard error is slightly larger relative to \(\hat{\mu}_{0.1}\), but it is still small.
set.seed(77)
ISLR2::Boston |>
specify(medv ~ NULL) |>
generate(reps = 5000, type = "bootstrap") |>
group_by(replicate) |>
summarize(medv_tenth_percentile = quantile(medv, probs = 0.1)) |>
summarize(se_medv_tenth_percentile = sd(medv_tenth_percentile))# A tibble: 1 × 1
se_medv_tenth_percentile
<dbl>
1 0.507