1 Strategy to implement machine learning solutions
In this chapter we will describe the strategy to use in order to use machine learning to increase the Return On Investment (ROI) for any company. Starting for understanding the problem until implementing the solution that solves the problem.
As this process is really complex we will use the Business Science Problem Framework (BSPF) as our main reference but we also complement it with more resources.
1.1 Business Science Problem Framework (BSPF)
1.1.1 View Business as a Machine
In this part we need to make sure that we are selecting a repetitive and measurable problem or improvement opportunity.
Isolate business unit
Define objetives
Define machine in terms of people and processes
Collect outcomes in terms of feedback
Feedback identifies problems
1.1.2 Understand the Drivers
Investigate if objectives are being met
Synthesize outcomes
Hypothesize drivers
1.1.3 Measure the Drivers
Collect data
Develop KPIs
1.1.4 Uncover Problems & Opportunities
Evaluate performance vs KPIs
Highlight potential problem areas
Review process and consider what could be missed or needed to answer questions
1.1.5 Encode Algorithms
Develop algorithms to predict and explain problem
Tie financial value of individual decisions to optimize for profit
Use recommendation algorithms to improve decisions
1.1.6 Measure Results
Capture outcomes after decision making system is implemented
Synthesize results in terms of good and bad outcomes identifying what was done and what happened
Visualize outcomes over time to determine progress
1.1.7 Report Financial Impact
Measure actual results
Tie to financial benefits
Report financial benefit of algorithms to key stakeholders
1.2 Modeling Process
According to Hands-on Machine Learning with R, we need to follow the next process to develop successful models:
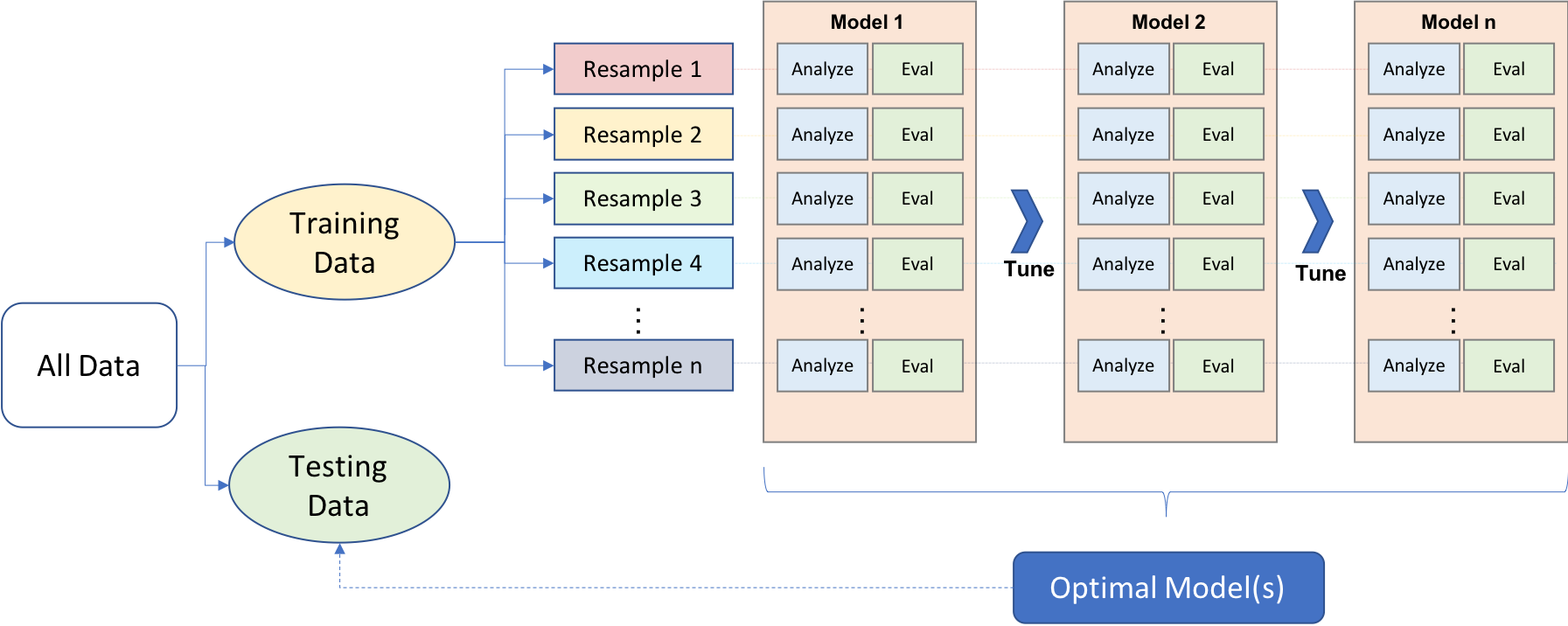
- Split the data by using simple random sampling for regression problems and stratified sampling for classification problems or if the response variable deviates strongly from normality in a regression problem. As result be will need to define 2 sets:
- Training set: To develop feature sets, train our algorithms, tune hyperparameters, compare models, and all of the other activities required to choose our final model. The proportion of data used in the set depends the amount of data that we have, if we have a lot data (n >100K) we can 60%, but if we don’t have much we can use 80%.
- Test set: To estimate an unbiased assessment of the model’s performance, which we refer to as the generalization error.
- Apply an intensive EDA to your data using graphics and unsupervised models in other to:
- Remove unnecessary variables
- Handle missing values
- Re-coding variable names and values
- Even though that Lasso and tree-based methods are resistant to non-informative predictors it better to remove them as with more features often becomes harder to interpret and is costly to compute. Based on the context we have 2 kind of variables to remove:
- Zero variance variables: The feature only contains a single unique value, provides no useful information to a model.
- Near-zero variance variables: The fraction of unique values over the sample size is low (say \(\leq 10\)%) and the ratio of the frequency of the most prevalent value to the frequency of the second most prevalent value is large (say \(\geq 20\)%). You can use
step_nzvto apply it. - High dimensional problem: It is an alternative approach to filter out non-informative features without manually removing them. It can be used to represent correlated variables with a smaller number of uncorrelated features (called principle components). Use
step_pcaorstep_plsto reduce the dimension of our features.
Perform imputation if required.
Solve the problems related to numeric features based on the model as they can affect GLMs, regularized regression, KNN, support vector machines and neural networks.
- Skewed: It can affect GLMs and regularized models. The recommended way it’s to use sqrt,log or Box-Cox for positive or
step_YeoJohnsonif the variable has negative numbers.
- Wide range in magnitudes: What are the largest and smallest values across all features and do they span several orders of magnitude?. It is often a good idea to standardize the features. Standardizing features includes centering and scaling so that numeric variables have zero mean and unit variance, which provides a common comparable unit of measure across all the variables.
- Transform categorical features as most models require that the predictors take numeric form. In this context, we can find:
- Levels with very few observations: To solve this we can collapse, or “lumping” these into a lesser number of categories by using the
step_otherand defining athresholdvalue to implement. Another alternative could be using a likelihood or effect encoding with theembed::step_lencode_glmfunction or the target encoding process which consists in replacing a categorical value with the mean (regression) or proportion (classification) of the target variable. - Models don’t manage categories: The most common is referred to as dummy encoding or one-hot encoding, where we transpose our categorical variables so that each level of the feature is represented as a boolean value and them removing the first level column. We can apply this transformation using
step_dummy, after standardizing the numeric variables. - Transform factors: If you have some ordered categorical features you can transform them using
step_ordinalscore()orstep_integer().
- Solve class imbalance problem by apply one of the next techniques:
- Down-sampling: If we have many observations, we can keep all samples in the rare class and randomly selecting an equal number of samples in the abundant class.
- Up-sampling: If we don’t have many observations, we can increasing the size of rarer samples by using repetition or bootstrapping.
- SMOTE: It’s a combination of over- and under-sampling is often successful and a common approach is known as Synthetic Minority Over-Sampling Technique. We can use this method with the function step_smote from the themis recipes extension package.
Use the training set to train the model. In most of the cases you will need to define a function
Y ~ X, but in some cases you will need variable with the predictors and another with the response or define the in argument with character names the variables to use as predictors and the variable to use a response.Confirm the performance of the model using resampling methods like k-fold cross validation which average k test errors, providing us with an approximation of the error we might expect on unseen data. Making sure to don’t fall into the data leakage by performing the feature engineering part in isolation of each resampling iteration.
Use the estimated test error to perform hyperparameter tuning across a grid search like
- Full Cartesian grid search: He assesses every hyperparameter value manually defined.
- Random grid searches: It explores randomly selected hyperparameter values from a range of possible values, early stopping which allows you to stop a grid search once reduction in the error stops.