## To manage relative paths
library(here)
## Publish data sets, models, and other R objects
library(pins)
library(qs2)
## To transform data that fits in RAM
library(data.table)
library(lubridate)
## To create plots
library(ggplot2)
library(ggiraph)
library(scales)
## Custom functions
devtools::load_all()
## Defining the print params to use in the report
options(datatable.print.nrows = 15, digits = 4)
# Defining the pin boards to use
BoardLocal <- board_folder(here("../NycTaxiPins/Board"))
# Loading params
Params <- yaml::read_yaml(here("params.yml"))Lookahead-Based Labeling for Learning an Improved ADP Policy
Generating the Supervised Target Variable take_current_trip from Historical Data
In the baseline simulation (Chapter 4) we used a myopic random policy that always accepts the first qualifying trip drawn from the candidate set \(\mathcal{C}_t^n\). That policy gave us the reference hourly wage of approximately $55.09.
To improve the policy we need a data-driven Policy Function Approximation (PFA). The first indispensable step is to create a high-quality supervised training set that approximates the optimal short-horizon decision \(x_t^*\).
For every historical trip \(i\) (treated as the current decision epoch) we:
- Reconstruct the exact state \(S_t\) used in the baseline.
- Build the identical candidate set \(\mathcal{C}_t\) that the driver would see in the next 15 minutes (same license, WAV rules, and discrete radius expansion).
- Calculate the performance metric (\(\text{perf}\)) for the current trip and all reachable alternatives \(j \in \mathcal{C}_t\). To ensure a fair comparison, the performance of future alternatives is penalized by the waiting time (\(\text{waiting\_secs}\)) between the decision epoch and the future request time.
- Label the binary target using an ambitious driver heuristic. The current trip is accepted only if its performance exceeds the 75th percentile of all identified future alternatives:
\[ \text{take\_current\_trip}_i = \begin{cases} 1 \text{ ("Y")} & \text{if } \text{perf}_i > Q_{0.75}(\{\text{perf}_j \mid j \in \mathcal{C}_t\}) \\ 0 \text{ ("N")} & \text{if } \text{perf}_i \le Q_{0.75}(\{\text{perf}_j \mid j \in \mathcal{C}_t\}) \end{cases} \]
This process is lookahead-based labeling via historical simulation. It is the standard offline technique in Approximate Dynamic Programming when perfect future information is unavailable. These labels will later be used to train a classifier \(\hat{p}_t = \Pr(\text{take\_current\_trip}=1 \mid S_t)\), turning the policy into a tunable threshold rule \(\tau\).
Loading packages and boards
Why this step is important
We load exactly the same board and custom functions used in the baseline simulation, guaranteeing reproducibility and identical data structures (zones, distances, WAV flags, etc.).
Adding take_current_trip to the sample
Purpose and ADP link
The new variable take_current_trip is the supervised label that approximates the optimal decision \(x_t^*\). It simulates an ambitious driver who keeps searching unless the current offer is significantly better than the top-tier local alternatives.
Assumptions (identical to baseline)
For a future trip to be considered a valid alternative it must satisfy exactly the constraints used in the baseline:
- Same taxi company: Matching
hvfhs_license_num. - WAV compatibility: A driver currently in a Wheelchair Accessible Vehicle (
wav_match_flag == "Y") is assumed to be WAV-capable and can see all future trips. Standard drivers can only seewav_request_flag == "N". - Time window: Request time must be between 3 seconds (rejection delay) and 15 minutes after the original request.
- Performance Calculation: Performance is calculated as:
\[ \frac{\text{driver\_pay} + \text{tips}}{(\text{trip\_time} + \text{waiting\_secs}) / 3600} \]
This ensures future trips are penalized by the opportunity cost of idling.
- Radius expansion: Distance from the current zone follows a discrete step-function:
- 1 mile (at 1 min)
- 3 miles (at 3 min)
- 5 miles (at 5 min)
- …up to 15 miles (at 15 min).
Implementation
Because the process is embarrassingly parallel and memory-intensive, we use future multicore processing. The core function add_take_current_trip() implements the 75th percentile logic and has been unit-tested to ensure the training labels are faithful to the baseline uncertainty model.
Tuning the parallel configuration
Why parallel processing matters: Running 500 k+ independent 15-minute simulations sequentially would take days. With 4 future cores + 8 data.table threads we complete the full 2023 dataset in a few hours without hitting swap memory.
Before scaling to the full year we benchmarked every combination of cores, chunk size, and scheduling. The optimal settings (data.table: 8 cores, future: 4 cores, chunk.size = 200, scheduling = 0.6) were selected because they minimized wall-clock time while staying inside the 17 GB RAM limit.
Why tuning is essential
A suboptimal configuration would either waste CPU cycles or crash the process. The chosen parameters give reproducible, efficient labeling at production scale.
Rscript ~/NycTaxi/multicore-scripts/01-fine-tune-future-process.RThe below plot summaries the obtained results.
And as we can see the got better performance by using fewer cores for future, due the RAM capacity limit, when using only 4 cores and increasing the number of task per core we can see the time needed to complete the 2k samples it’s reduced as it didn’t use the SWAP memory while running the process, as we can see in the next screenshot.
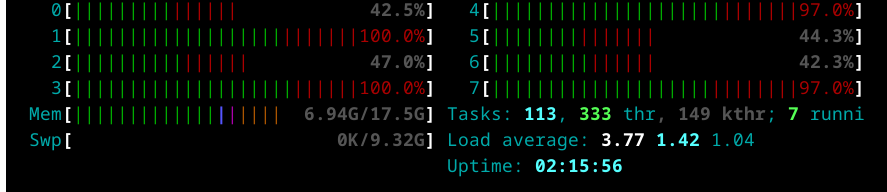
And after checking this results we ended with the next configuration:
- Number of cores used by
data.table: 8 - Number of cores used by
future: 4 - Chunk.size used by
future: 200 - Scheduling used by
future: 0.6
Running the process month-by-month
We execute one month at a time via the bash script 02-run_add_target.sh to protect against interruptions and memory overflow.
Why month-by-month execution matters
It turns a high-risk, all-or-nothing job into a fault-tolerant pipeline. We can resume from any month without reprocessing prior data.
#!/bin/bash
# Check if the correct number of arguments is provided
if [ "$#" -ne 3 ]; then
echo "Usage: $0 <script_path> <start_number> <end_number>"
exit 1
fi
# Assign arguments to variables
SCRIPT_PATH=$1
START_NUM=$2
END_NUM=$3
# Loop through the given range and run the R script
for i in $(seq $START_NUM $END_NUM)
do
Rscript $SCRIPT_PATH $i
doneOnce defined the bash script we can use it by running the next command in the terminal.
bash multicore-scripts/02-run_add_target.sh multicore-scripts/02-add-target.R 1 24# Loading Packages ----
## To transform data that fits in RAM
library(data.table)
library(lubridate)
library(future)
## To import and export data frames as binary files
library(pins)
## To manage relative paths
library(here)
## Custom functions
devtools::load_all()
# Defining the pin boards to use
BoardLocal <- board_folder(here("../NycTaxiPins/Board"))
# Importing data ----
PointMeanDistance <- BoardLocal |> pin_read("PointMeanDistance")
ValidZoneSample <- BoardLocal |> pin_read("ValidZoneSample")
# Selecting the data to use -----
ValidZoneSampleByMonth <-
## Excluding trips that took place in the last 15 min minutes
## to be able to run this process month by month as solution
## to avoid running the process on disk which can be really slow
ValidZoneSample[, request_datetime_extra := request_datetime + minutes(15)][
floor_date(request_datetime_extra, unit = "month") ==
floor_date(request_datetime, unit = "month"),
.(data = list(.SD)),
keyby = c("year", "month"),
.SDcols = !c("request_datetime_extra")
## Adding parquet files for each month
][,
source_path := dir(
here("../NycTaxiBigFiles/trip-data/"),
recursive = TRUE,
full.names = TRUE
)
]
# Running parallel process
## Defining configuration to use
options(future.globals.maxSize = 20 * 1e9)
data.table::setDTthreads(8)
plan(multicore, workers = 4)
## Getting month number from terminal
month_i <- commandArgs(TRUE) |> as.integer()
## Running the process
OneMonthData <-
add_take_current_trip(
ValidZoneSampleByMonth[month_i, data[[1L]]],
point_mean_distance = PointMeanDistance,
parquet_path = ValidZoneSampleByMonth[month_i, source_path],
future.scheduling = 0.6,
future.chunk.size = 200
)
# Saving results -----
if (nchar(month_i) == 1L) {
month_i = paste0("0", month_i)
}
FileName <- paste0("OneMonthData", month_i)
BoardLocal |>
pin_write(OneMonthData, paste0(OneMonthData, month_i), type = "qs2")
print(FileName)Here we can see that the 24 files have been saved as fst binnary files.
BoardLocal |> pin_list() |> grep(pattern = "OneMonth", value = TRUE) |> sort()
#> [1] "OneMonthData01" "OneMonthData02" "OneMonthData03" "OneMonthData04"
#> [5] "OneMonthData05" "OneMonthData06" "OneMonthData07" "OneMonthData08"
#> [9] "OneMonthData09" "OneMonthData10" "OneMonthData11" "OneMonthData12"
#> [13] "OneMonthData13" "OneMonthData14" "OneMonthData15" "OneMonthData16"
#> [17] "OneMonthData17" "OneMonthData18" "OneMonthData19" "OneMonthData20"
#> [21] "OneMonthData21" "OneMonthData22" "OneMonthData23" "OneMonthData24"Predictor Analysis
Distribution of the target
The analysis shows that approximately 24% of trips are rejected under the 75th percentile lookahead rule. This indicates that in nearly a quarter of cases, the current trip’s performance—even when accounting for its immediate availability—is inferior to the high-performance “ambitious” threshold of potential future alternatives.
Show the code
# Importing data
ValidZoneSample2022 <-
pin_list(BoardLocal) |>
grep(pattern = "^OneMonthData", value = TRUE) |>
sort() |>
head(12L) |>
lapply(FUN = pin_read, board = BoardLocal) |>
rbindlist()
ZoneCodesRef <- pin_read(BoardLocal, "ZoneCodesRef")
ValidZoneSample2022[, `:=`(
company = fcase(
hvfhs_license_num == "HV0002" , "Juno" ,
hvfhs_license_num == "HV0003" , "Uber" ,
hvfhs_license_num == "HV0004" , "Via" ,
hvfhs_license_num == "HV0005" , "Lyft"
),
take_current_trip = factor(
fifelse(take_current_trip == 1, "Y", "N"),
levels = c("Y", "N")
),
weekday = wday(request_datetime, label = TRUE, abbr = FALSE, week_start = 1),
month = month(request_datetime, label = TRUE, abbr = FALSE),
hour = hour(request_datetime),
trip_time_min = trip_time / 60,
trip_value = tips + driver_pay,
PULocationID = as.character(PULocationID),
DOLocationID = as.character(DOLocationID)
)]
# To explore the distribution provided by the `PULocationID` (Pick Up Zone ID)
# and `DOLocationID` (Drop Off Zone ID), we need to add extra information.
# If we check the taxi zone look up table, we can find the `Borough` and
# `service_zone` of each table.
ValidZoneSample2022[
ZoneCodesRef,
on = c("PULocationID" = "LocationID"),
`:=`(
PULocationID = as.character(PULocationID),
PUBorough = Borough,
PUServiceZone = service_zone
)
]
ValidZoneSample2022[
ZoneCodesRef,
on = c("DOLocationID" = "LocationID"),
`:=`(
DOLocationID = as.character(DOLocationID),
DOBorough = Borough,
DOServiceZone = service_zone
)
]
ValidZoneSample2022[, .N, by = "take_current_trip"][, `:=`(
prop = N / sum(N),
take_current_trip = reorder(take_current_trip, N)
)] |>
ggplot(aes(N, take_current_trip)) +
geom_col(fill = Params$ColorGray, color = "black", width = 0.5) +
geom_text(aes(label = percent(prop, accuracy = 1)), nudge_x = 10000) +
scale_x_continuous(labels = comma_format()) +
labs(title = "Only 24% of the trips need to be rejected", x = "") +
theme_minimal(base_family = Params$BaseFontFamily) +
theme(
panel.grid.major.y = element_blank(),
panel.grid.minor.x = element_blank(),
plot.title = element_text(face = "bold", size = 15)
)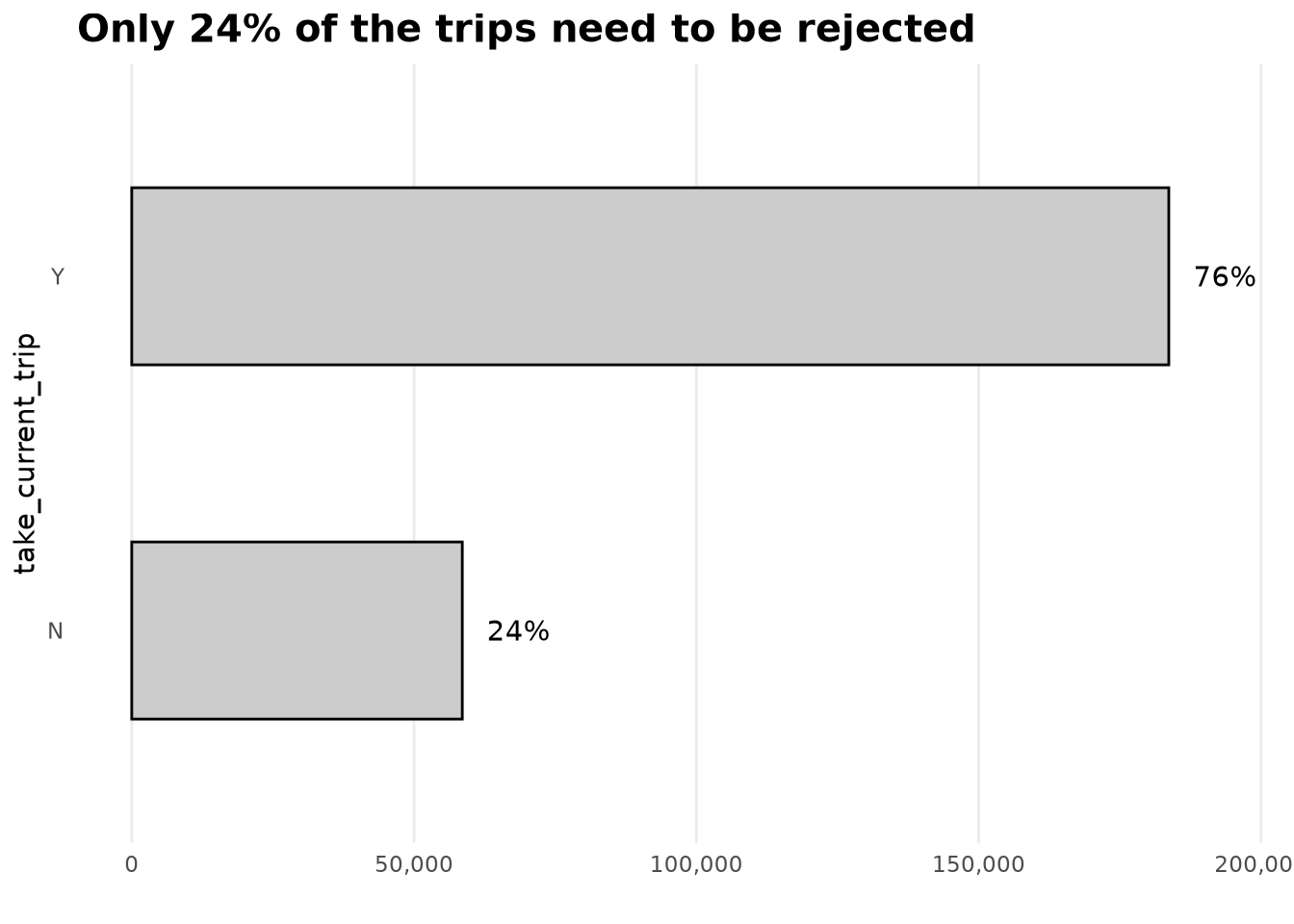
Predictors vs take_current_trip
We restrict analysis to trips ≥ 2 minutes (as decided in the baseline) and explore only variables with ≥ 2 levels and ≥ 1 % representation.
Categorical variables
dispatching_base_num,originating_base_num, andaccess_a_ride_flagwere not included as represent the same information that thecompany.PULocationIDandDOLocationIDpresent a strong variation.wav_match_flagpresent a moderate variation.companypresent a moderate variation.weekdaypresent low variation.monthpresent a moderate variation.hourpresent a strong variation.PUBoroughpresent a strong variation.PUServiceZonepresent a strong variation.DOBoroughpresent a strong variation.DOServiceZonepresent a strong variation.
Numerical variables
trip_milesalone is not highly effective in predicting whether a trip will be taken as but classes present overlapping distributions and similar cumulative distributions, which make it a low predictor.trip_time_minalone is not highly effective in predicting whether a trip will be taken as both classes present overlapping distributions and similar cumulative distributions, which make it a low predictor.
Show the code
TrainingSampleValidCat <-
ValidZoneSample2022[
trip_time_min >= 2,
c(.SD, list("trip_id" = trip_id)) |> lapply(as.character),
.SDcols = \(x) is.character(x) | is.factor(x) | is.integer(x)
][,
melt(.SD, id.vars = c("trip_id", "take_current_trip")),
.SDcols = !c(
"hvfhs_license_num",
"dispatching_base_num",
"originating_base_num",
"access_a_ride_flag"
)
][, value_count := .N, by = c("variable", "value")][,
value_prop := value_count / .N,
by = "variable"
][value_prop >= 0.01][, n_unique_values := uniqueN(value), by = "variable"][
n_unique_values > 1L
]
ggplot(
TrainingSampleValidCat,
aes(value, fill = factor(take_current_trip, levels = c("Y", "N")))
) +
geom_bar(width = 0.7, position = "fill") +
scale_fill_manual(
values = c("N" = Params$ColorHighlight, "Y" = Params$ColorGray)
) +
scale_y_continuous(labels = percent_format(accuracy = 1)) +
facet_wrap(vars(variable), scale = "free", ncol = 3) +
coord_flip() +
labs(y = "Prop of trips", fill = "take_current_trip") +
theme_minimal(base_family = Params$BaseFontFamily) +
theme(legend.position = "top", panel.grid = element_blank())
Show the code
plot_num_distribution(
ValidZoneSample2022[trip_time_min >= 2],
trip_miles,
title = "trip_miles",
take_current_trip,
manual_fill_values = c("N" = Params$ColorHighlight, "Y" = Params$ColorGray),
hist_binwidth = 5,
hist_n_break = 12,
log_binwidth = 0.5,
curve_limits = c(0, 25),
curve_breaks_x = breaks_width(3)
)
#> Warning: Removed 489 rows containing non-finite outside the scale range
#> (`stat_ecdf()`).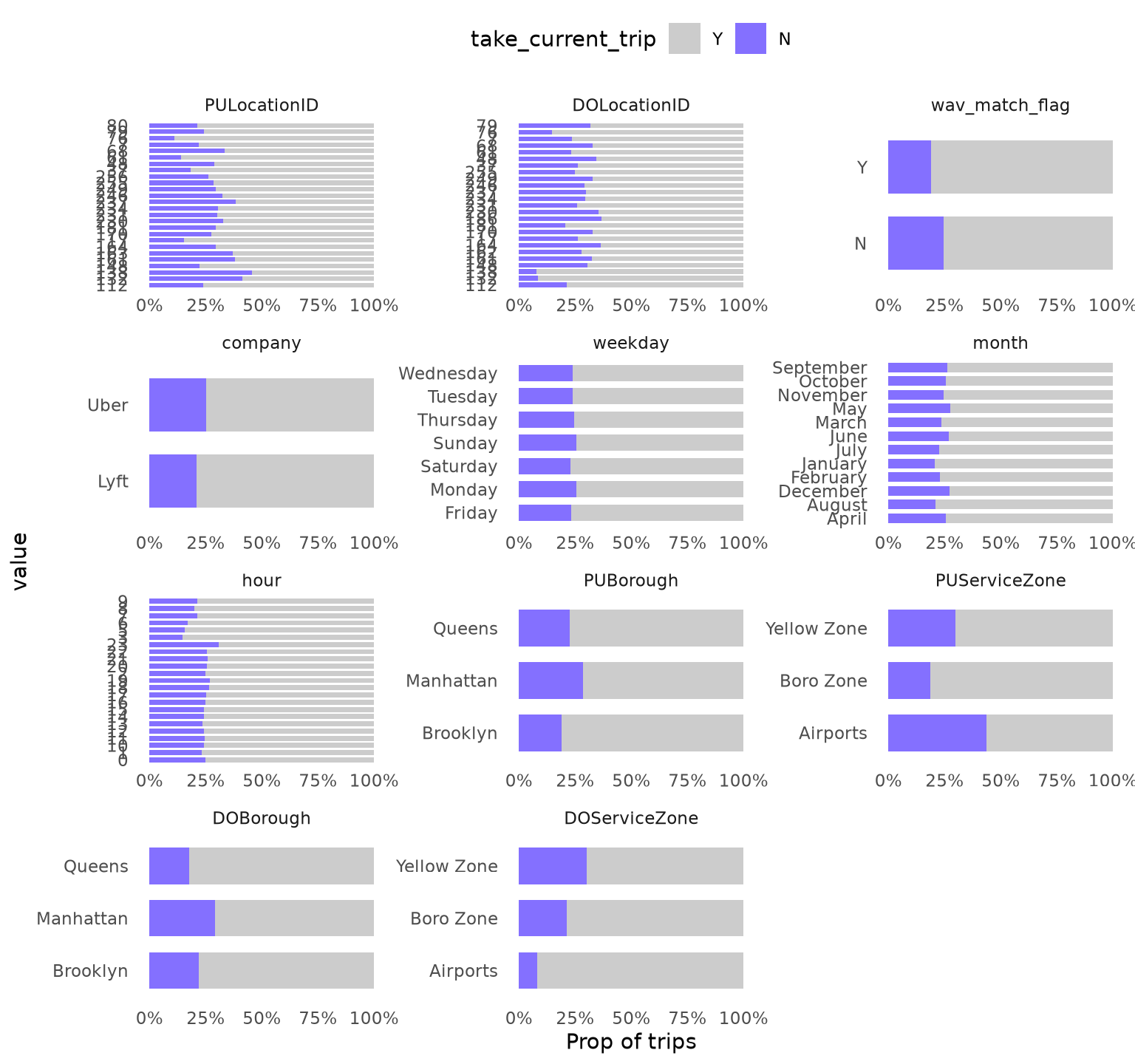
Show the code
plot_num_distribution(
ValidZoneSample2022[trip_time_min >= 2],
trip_time_min,
take_current_trip,
manual_fill_values = c("N" = Params$ColorHighlight, "Y" = Params$ColorGray),
title = "trip_time_min",
hist_binwidth = 5,
hist_n_break = 12,
log_binwidth = 0.5,
curve_breaks_x = scales::breaks_width(10),
curve_limits = c(0, 90)
)
#> Warning: Removed 460 rows containing non-finite outside the scale range
#> (`stat_ecdf()`).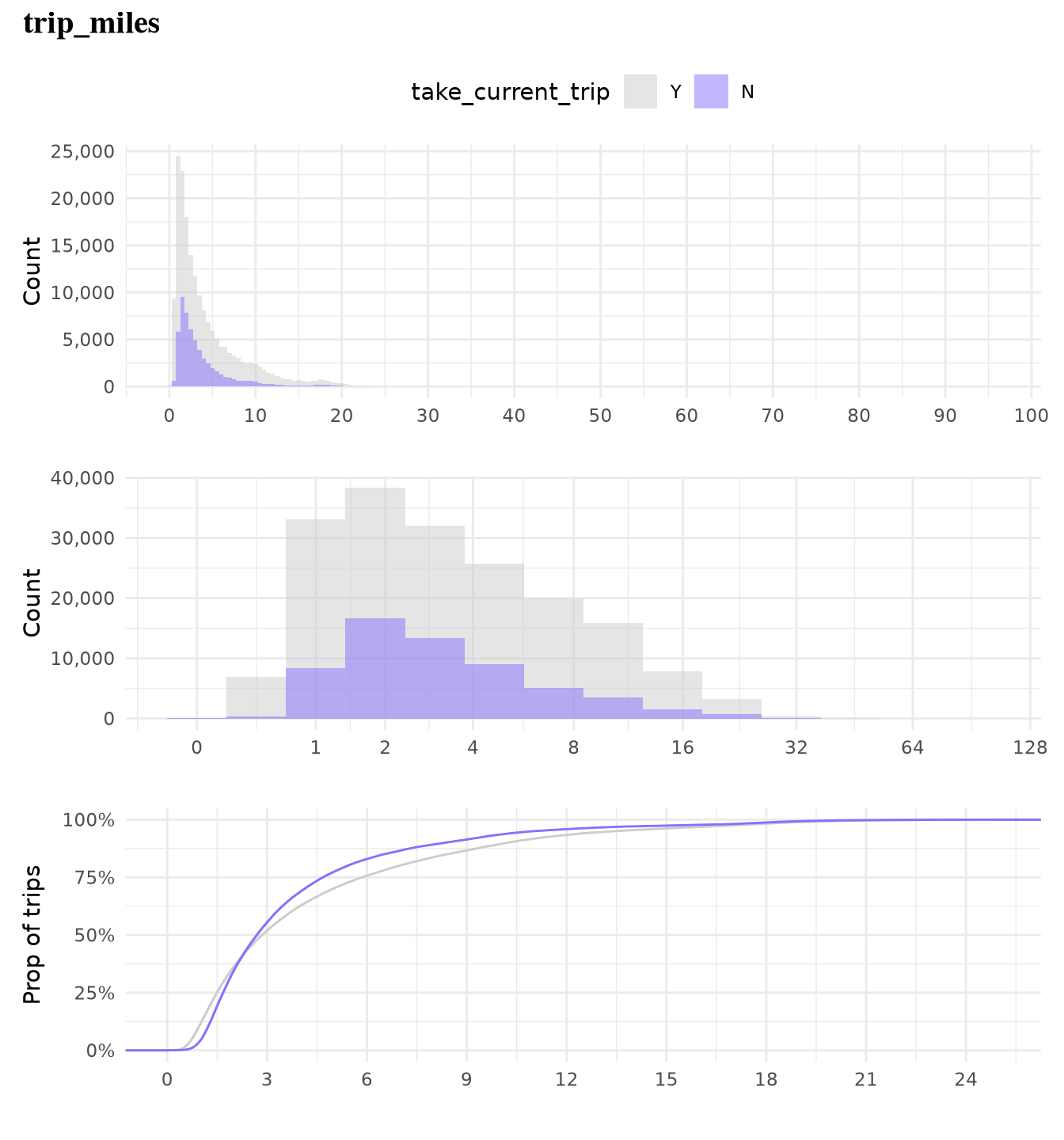
Why the predictor analysis matters
It tells us which features carry signal for the PFA classifier. Strong variation in hour, borough, and location IDs confirms that the state variables we used in the baseline simulation are indeed predictive of the optimal decision under an ambitious heuristic.
Forward link to the next chapter
We now possess a clean, large-scale, labeled dataset where the target variable represents an ambitious, high-performance decision. Unlike the myopic baseline, these labels account for the opportunity cost of waiting time and the statistical distribution of local trip values.
In the next chapter, we will train a classifier to approximate this selective behavior, turning the probability output into a tunable threshold policy \(\pi^\tau\). By re-running the full-day empirical simulation (Monte-Carlo averaging) from Chapter 4, we will be able to measure exactly how much an “ambitious” lookahead strategy improves the driver’s hourly wage compared to the myopic starting point.